
Heading 2
Big Data and Analytics - What's next? (Part 1)
Discover the basics of big data and analytics in this informative guide. Learn about key concepts, tools, and techniques for businesses with factors.ai
Written by

Aravind Murthy
Co-Founder
Summarize this article


.svg)


Apache Hadoop, Hive, Map reduce, TensorFlow etc. These and a lot of similar tems come to mind when some one says Big Data and Analytics. It can mean a lot of things, but in this blog we will restrict it to the context of - analytics done on relatively structured data, collected by enterprises to improve the product or business.
When I started my career as an engineer in Google around a decade back, I was introduced for the first time to MapReduce, Bigtable etc in my first week itself. These were completely unheard of outside and seemed like technologies accessible and useful to only a select few in big companies. Yet, within a few years, there were small shops and training institutes springing up to teach Big Data and Hadoop, even in the most inaccessible lanes of Bangalore.
It’s important to understand how these technologies evolved or rather exploded, before we dwell upon the next logical step.
Dawn of time
Since the dawn of time (or rather the unix timestamp), the world was ruled by Relational Databases. Relational Databases are something that most engineers are familiar with. Data is divided into (or normalized) into logical structures called tables. But these tables are not completely independent and related to each other using foreign keys. Foreign keys are data entries that are common across tables.
Take the example of data from a retail store. The database could have 3 tables, one for the Products it sells, one for Customers of the store and one for Orders of the products bought in the store. Each entity can have multiple attributes and is stored in different columns of the corresponding table. Each data point is stored as rows in the table. The Orders table contains entries of products bought by different customers and hence related to both Products and Customers table, using the columns product_id and customer_id.
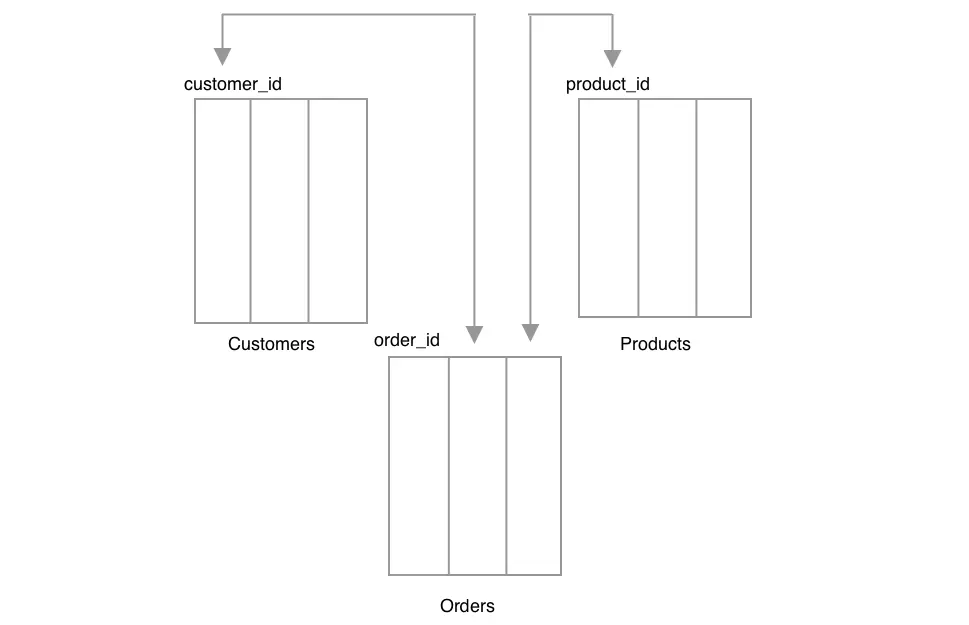
Few implications of this structure are
- Since each data unit is split across tables, most updates would involve updating multiple tables at once. Hence transaction guarantees are important here, wherein you either update all the tables or none at all.
- Data can be fetched almost any way you want. For example, we can fetch all orders bought by a specific customer or all customers who bought a specific product. Additional indices can be defined on columns to speed up retrieval. But since data is split across tables, it sometimes could involve costly joins when matching the related items across tables.
SQL (Structured Query Language) became the de facto standard to query these databases and thus SQL databases also became the namesake for relational databases. These served the needs of all enterprises. As the data grew, people moved to bigger and better database servers.
Rise of Internet
Then in the 90’s there was the internet. One of the limitations of the SQL database is that it needs to reside in one machine, to provide the transactional guarantees and to maintain relationships. Companies like Google and Amazon that were operating at internet scale realized that SQL could no longer scale to their needs. Further, the data model did not need to maintain complex relationships.
If you were to store and retrieve the data unit as a whole, rather in parts across tables then each data unit is self contained and independent of other data. The data can now be distributed to different machines, since there are no relationships to maintain across machines.
Google for instance wanted to store and retrieve the information about a webpage only by it’s url and Amazon product information by product_id. Google published a paper on Bigtable in 2006 and Amazon on DynamoDB in 2007, of their inhouse built distributed databases. While DynamoDB stored data as key value pairs, Bigtable stored data by dividing data into row and columns. Lookups can be done by row key in both databases, but in Bigtable only the data in the same column family were co-located and could be accessed together. Given a list of rows and columns of interest, only those machines which held the data were queried and scanned.
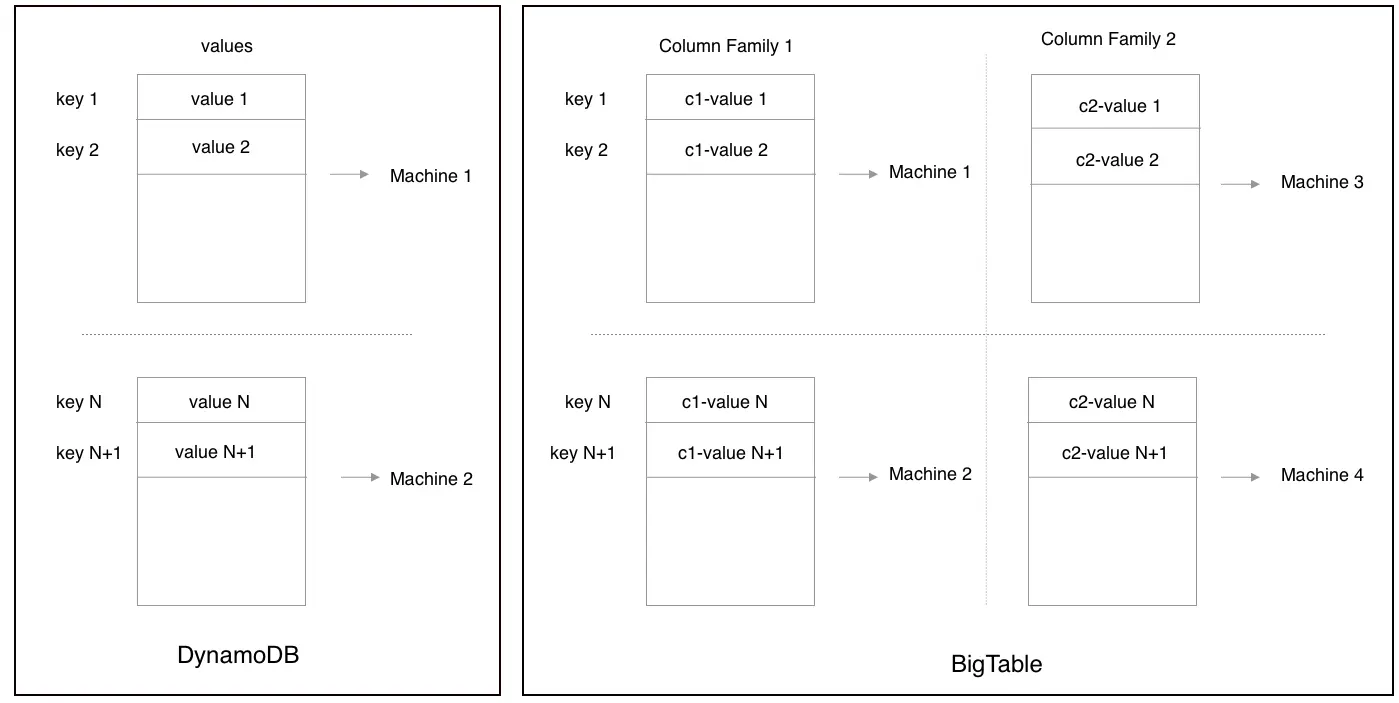
Now you no longer needed bigger and better machines to scale. So the mantra changed from bigger and super machines, to cheap or commodity hardware with excellent software. And since hardware was assumed to be unreliable, the same data had to be replicated and served from multiple machines to avoid loss of data.
Open source projects soon followed suit. Based on different tradeoffs of read and write latencies, assumptions in the data model and flexibility when retrieving data we now have plethora of distributed databases to choose from. HBase, MongoDB, Cassandra to name a few. Since these databases were not relational or SQL they came to be known as NoSQL databases.
{{INLINE_TOFU}}
Related Big Data Technologies
This fundamental change in databases also came with auxiliary changes on how data was stored and used for computation. Most data is stored on files. But now, these files should be accessible from any of the machine. These files could also grow to be very large. And files should not be lost when a machine goes down.
Google solved it by breaking files into chunks of almost equal sizes and distributing and replicating these chunks across machines. Files were accessible within a single namespace. A paper on this distributed file system called GFS was published way back in 2003. Bigtable was infact built on top of GFS.
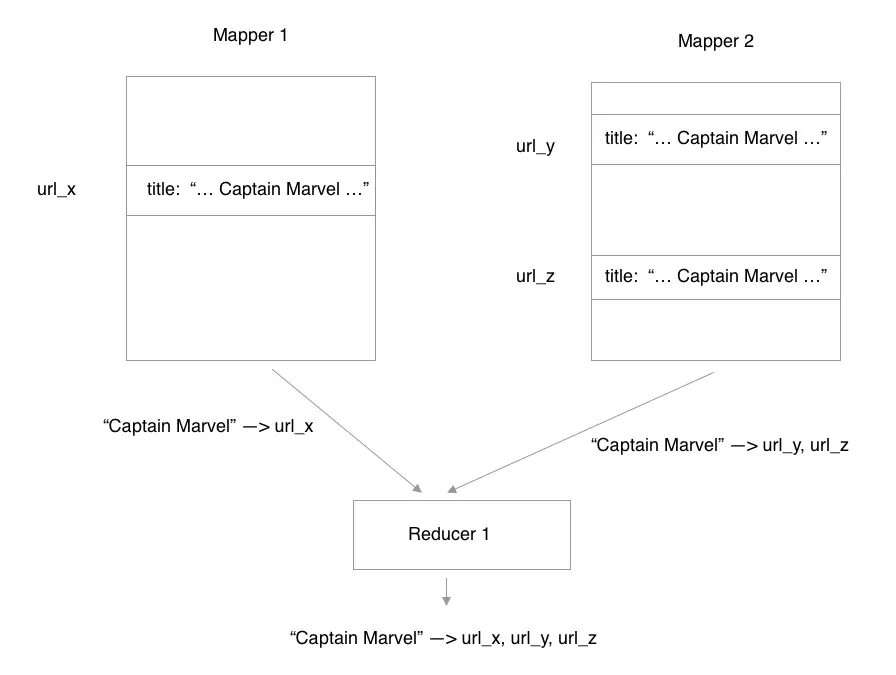
Distributed databases allowed you to access data only in one way (or a couple of ways) using keys. It was not possible to access data based on the values present inside the data units. In SQL you can create index on any column and access data based on the values in it. Take the example of Google storing web pages, you could access information about a webpage using url cnn.com (row key). Or you could get the links in a given webpage using rowkey (cnn.com) and a column key (links). But how do you get urls of web pages that contain the word say “Captain Marvel”.
So if the data needed to be accessed in a different way, it had to be transformed, such that data units that are related to each other by the values it holds come together. The technology used to do that was Map-Reduce. It had two phases - First it loads the data in chunks into different machines. All the urls of pages that contain the word “Captain Marvel” are sent to other process called Reducer, which collects and outputs all the matched urls. It usually requires pipelines of map reduces for more complex data transformation and joining data across different sources. This MapReduce framework was generic enough to perform various distributed computation tasks and became the de facto standard for distributed computing. The paper on MapReduce was published by Google in 2004.
Yahoo, soon took cue and developed and open sourced these technologies, which we all know as Hadoop, later adopted by Apache. Now if Map-Reduces can be used to transform data, it could also be used to retrieve data that match a query. Technologies like Apache Hive, Dremel, BigQuery etc were developed, which allowed user to fire SQL queries on large amounts of structured data, but the results were actually delivered by running Map Reduces in the background. An alternative to loading data into a different machine and then compute on top of it, is to take computation closer to where the data reside. Frameworks like Apache Spark, were developed broadly on this philosophy.
In the next blog, we will see some of the current trends of these technologies and discuss on how we think the these will evolve.

See how Factors can 2x your ROI
Boost your LinkedIn ROI in no time using data-driven insights
Try AdPilot Today


.avif)


.avif)

See Factors in action.
Schedule a personalized demo or sign up to get started for free
LinkedIn Marketing Partner
GDPR & SOC2 Type II

.svg)












.png)